File and file group VLDB very large database.
There are many factors needs to be looked carefully. Let me put some important points.
Choosing a storage hardware & Physical database layout – like Dell compellent, 8 GBs FC
Creating a database with physical file layout- File and file group.
Layout the logical database files – Like Table Partitioning – Indexes are same file group.
Maintenance job for VLDBs – Easy of Backup, piecemeal restore, split checkDB and reindex for TP, TempDB no of file.
Overview:
Example of new application requirement: The database load data every current year data to the database. Per year ~ 2TB. There will be minimal write is going to happen to the historical/ archive data, create a data files for future years as well. Since, this is a big data warehouse application which should keep minimum 10 years of data, with automated table partitioning.
There was a case for to migrate a default standalone database with one MDF and LDF to alwaysON file and file group. Since, the one MDF file is 1 TB and the database application can grow up to 20TB, 2TB/year and we cannot delete 10 years of data. It was a two time migration. From Physical to virtual and virtual to virtual for business reason (using an existing cluster A/A with low end storage and moved to dedicated A/P with high end storage).
Existing server and disk was in MBR and limit to 2TB, we have to move to GPT and should not running out of drive letters – mount point.
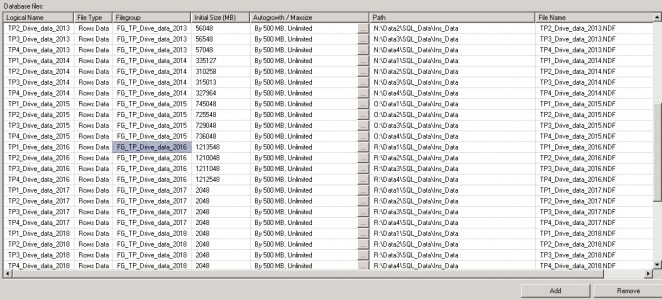
A typical file and file group setup
We need to store a data year from 2008 to 2020. Four files per year i.e. 4 files * 13 years =52 data files, distribute each file to the dedicated disk per year. Ex: 2008 data will be distribute to W,X,Y& Z drives. The VMDks and controllers are configured depends on the read and write of the data and historical, primary data files, current transactional and future transactional based.
It is always good to sit with VM and storage admin, when we do a VLDB configuration. Like how the LUNs are mounted and the controllers for the VMDK/partitions are configured. Test everything and make a benchmark.
In windows 2012 can create sub partition. We created a root and sub partitions.
We have used automated tired storage, which does not mean we do not need a table partitioning, still we need it and maybe, the data placement like historical data into a RAID 5 and current year data into the RAID 10 is not the case on automated tired storage.
How to migrate standalone VLDB database to alwaysON file and file group with the minimal downtime – You can choose (Backup and restore like mounting directly to DC as external HDD copy to new hardware and restore with norecovery, when the cut-over start do a differential and log.
On VM, the VMDKs are easily un-mount and mount to new server and very fast, you can detach attach the databases as well. OR you can do VM back end without downtime, with some slowness)
File and File group and partition implementation
What is file and file group, How it works & Design & Performance, Advantages of file and group.
File and file group:
File and file group is a method to allow more data files can be added into a single file group the files can be distribute/speared across the drives/partitions. It commonly used to increase scalability, improve the IO throughput and speedup backup/restore operations.
By default, SQL will create a database with one data file (MDF), one log file (LDF) and the one primary filegroup, which is default always, so all the tables, indexes are going to store only in a single filegroup – Primary FG.
Ex: Create table t_test (no int) [on primary]– on primary is an optional.
This is really a good configuration from Microsoft, but majority of us does not use this option. I generally use the file and file group method for the database grows over 500+ GB, it is good to use file and file group, even if all the partitions are coming from single physical disk. It will give more control, easier to management and help us to implement additional features in the future, like backup and restore, checkDB and table partitioning etc, but performance wise no difference.
In general, DBA get a bit fear of using this file and file group, since it is not a default configuration. It is very easy, if we understand the working mechanism.
File and file group working mechanism
File and file group uses two algorithm 1. Round robin 2. Proportional fill
Round robin is nothing but, it will help the files to grow in a circular fashion within the file group and Proportional fill figure out, how to fill the files proportionally/ uniformly. Proportional fill works based on the free space within a file.
Example: If you have file group called “FG_Current_Data” with five file (F1.mdf, F2.ndf, F3.ndf, F4.ndf& F5.ndf) with all initial size 10 MB and free space 5 MB, when you insert a data all the five will grow equally. If you have one file big with lots of free space, then the Proportional fill figure out, where the file has huge free space, it will ask that file to grow first and when it is comes all equal with free space, it will use the round robin. We can also ignore the Proportional fill this by using a trace flag 1117.
A database can have multiple file groups and a filegroup can have multiple data files.
Let us Test and see how the mechanism works
Test in various scenario, which is good for your case.
Test the proportional fill algorithm
- Create all the data files with equal size –Test it yourself. It is easy one.
- Create a big one data file and remaining are equal in free space – With and without enabling trace flag 1117.
Use the following script:
You have to open two query windows 1. Creating test scripts 2. Check the space available. You have to go one by one insert and note it in the excel file, can easily correlate.
Check the trace status and enable and disable for the test.
/*
1. Create equal size of data files - Try yourself
2. Create a big one data file and remaining are equal in free space
3. Run with and without trace flag 1117
*/
select @@version -- Microsoft SQL Server 2012 (SP4) (KB4018073) - 11.0.7001.0 (X64)
-- dbcc tracestatus
-- dbcc traceoff(1117,-1)
USE [master]
GO
alter database [FG_3] set single_user with rollback immediate
drop database [FG_3]
USE [master]
GO
-- select 5*1024
/****** Object: Database [FG_3] Script Date: 8/12/2016 10:29:42 PM ******/
CREATE DATABASE [FG_3]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'FG_3_PRIMARY_1', FILENAME = N'D:\SQL_Data\FG_3_PRIMARY_1.mdf' , SIZE = 10072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ),
( NAME = N'FG_3_PRIMARY_2', FILENAME = N'D:\SQL_Data\FG_3_PRIMARY_2.ndf' , SIZE = 10072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ),
( NAME = N'FG_3_PRIMARY_3', FILENAME = N'D:\SQL_Data\FG_3_PRIMARY_3.ndf' , SIZE = 10072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ),
FILEGROUP [Historical_data]
( NAME = N'FG_3_Historical_data_1', FILENAME = N'D:\SQL_Data\FG_3_Historical_data_1.ndf' , SIZE = 100072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 10072KB ),
( NAME = N'FG_3_Historical_data_2', FILENAME = N'D:\SQL_Data\FG_3_Historical_data_2.ndf' , SIZE = 10072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 5072KB )
,( NAME = N'FG_3_Historical_data_3', FILENAME = N'D:\SQL_Data\FG_3_Historical_data_3.ndf' , SIZE = 10072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 10072KB )
LOG ON
( NAME = N'FG_1_log', FILENAME = N'D:\SQL_Data\FG_3_log.ldf' , SIZE = 10072KB , MAXSIZE = UNLIMITED , FILEGROWTH = 1024KB )
GO
-- Create table in primary
use [FG_3]
create table t_data_load (n int identity, n1 char(8000))
on [Historical_data]
-- First insert
insert into t_data_load (n1) values ('dummy');
go 10000
-- Second insert
insert into t_data_load (n1) values ('dummy');
go 5000
--select 15000*8096
--select 121440000/1024.0/1024.0 -- 115.814208984375
----------------
insert into t_data_load (n1) values ('dummy');
go 1000
select count(*) from t_data_load
insert into t_data_load (n1) values ('dummy');
go 1000
insert into t_data_load (n1) values ('dummy');
go 1000
-- Add 3 data file
USE [master]
GO
ALTER DATABASE [FG_3] ADD FILE ( NAME = N'FG_3_Historical_data_4', FILENAME = N'D:\SQL_Data\FG_3_Historical_data_4.ndf' , SIZE = 10072KB , FILEGROWTH = 10072KB ) TO FILEGROUP [Historical_data]
GO
ALTER DATABASE [FG_3] ADD FILE ( NAME = N'FG_3_Historical_data_5', FILENAME = N'D:\SQL_Data\FG_3_Historical_data_5.ndf' , SIZE = 10072KB , FILEGROWTH = 10072KB ) TO FILEGROUP [Historical_data]
GO
ALTER DATABASE [FG_3] ADD FILE ( NAME = N'FG_3_Historical_data_6', FILENAME = N'D:\SQL_Data\FG_3_Historical_data_6.ndf' , SIZE = 10072KB , FILEGROWTH = 10072KB ) TO FILEGROUP [Historical_data]
GO
-- select 8000*100
-- Create table in primary
use [FG_3]
-- First insert
insert into t_data_load (n1) values ('dummy');
go 5000
/*
-- Second insert
insert into t_data_load (n1) values ('dummy');
go 5000
-- Third insert
insert into t_data_load (n1) values ('dummy');
go 5000
*/
Free space:
use [FG_3] go -- olny for file groups SELECT MF.NAME AS FILENAME, SIZE/128.0 AS CURRENTSIZE_MB, SIZE/128.0 - ((SIZE/128.0) - CAST(FILEPROPERTY(mf.NAME, 'SPACEUSED') AS INT)/128.0) AS USEDSPACE_MB, SIZE/128.0 - CAST(FILEPROPERTY(mf.NAME, 'SPACEUSED') AS INT)/128.0 AS FREESPACEMB, PHYSICAL_NAME,DATABASEPROPERTYEX (DB_NAME(),'RECOVERY') AS RECOVERY_MODEL,mf.TYPE_DESC, CASE WHEN IS_PERCENT_GROWTH = 0 THEN LTRIM(STR(GROWTH * 8.0 / 1024,10,1)) + ' MB, ' ELSE 'BY ' + CAST(GROWTH AS VARCHAR) + ' PERCENT, 'END + CASE WHEN MAX_SIZE = -1 THEN 'UNRESTRICTED GROWTH' ELSE 'RESTRICTED GROWTH TO ' +LTRIM(STR(MAX_SIZE * 8.0 / 1024,10,1)) + ' MB' END AS AUTO_GROW FROM SYS.MASTER_FILES MF join sys.filegroups SF on MF.data_space_id =SF.data_space_id WHERE DATABASE_ID = DB_ID() and MF.NAME not like '%primary%' order by CURRENTSIZE_MB desc
Form Microsoft: Proportional fill algorithm & Round robin
Proportional fill – It works based on the free space available in the file. Larger free space file will grow first.
Round robin – It works based on the auto growth in the file. Once it filled the given auto growth, it will move to the next file.
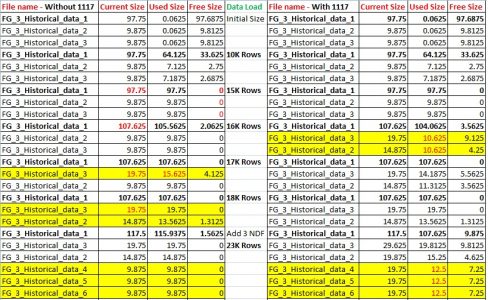
I have created the file with one big size and remaining are same size to understand better.
- The proportional fill algorithm work on the file which has large free space – In our case “FG_3_Historical_data_1” – 97.68 MB free.
-
It will first fill larger and when it fills all the free space within the file and all other files comes in equal free space – 0 MB.
-
It will ask for an auto growth, in our example 10MB, here comes the Round robin. – It will grow 10MB, 97.68+10 MB = 107.6 MB.
-
It will move to the next file, our case “FG_3_Historical_data_3”and fill the 10 MB auto growth – 9.8 MB +10 MB = 19.8 MB
-
It will move to next file our case “FG_3_Historical_data_2” and will fill the 10 MB auto growth – 9.8 MB +10 MB = 19.8 MB and will move back to file 1.
When we have a trace flag 1117 enabled, the proportional work on the file which has large free space, it will fill first and when it fills all the free space and ask for an auto growth, in our example 10MB, it will auto growth all the files 1+2+3 and fill uniformly.
In my case, the primary MDF is 1 TB, I just disabled the auto growth and created three files in the primary file group and pointed those files in separate partition/ mount point.
The case, when we have some file with large used size and we want to add some more files into an existing filegroup, you can create a same file size as an existing one with same auto growth, so that it can come in the same size as your existing file, the theory is it should have more free space than the existing file, later you can match and change the auto growth to same for all files.
Ex: If you have a two file with 50MB and want to add two more files into the same filegroup. Try yourself with one dummy database. For small data set this is ok, but for larger 1TB, this is not going to be work. Just you can disable the auto growth for an existing and add new files.
Implement Table partitioning
Table partitioning is a way to divide a large table into smaller pieces as a partition. In general, we do partition for larger tables to achieve data, importantly index rebuild. You can make a existing larger table to table partition and move data across the drive.
TP is a big topic and it needs a another post.