
This month’s TSQL Tuesday party is being hosted by Stuart R Ainsworth (Blog| Twitter). I am very glad to write my first blog post as t-SQL Tuesday post on my newly designed website.
SQL server has three types of internal joins. I know most of folks never heard this join type because it’s not logical join and it’s not often used in their codes.
Then, when it will be used?
Well the answer is “it depends”.
This means it depends upon the record sets and indexes. The query optimizer will be smart and always try to pick up the most optimal physical joins. As we know SQL optimizer creates a plan cost based and depends upon the query cost it will choose the best join.
How the query optimizer will choose the join type internally?
Well, there is some algorithm has written internally for the query optimizer to choose the join type.
Let’s go for some practical examples and will finally summarize it.
First I will give some basic idea how the join will work and when/How the optimizer will decide to use anyone of the internal join (Physical join).
• It depends upon the table size
• It depends upon the index on the join column
• It depends upon the Sorted order on the join column
Test:
The test has done by following configuration.
RAM: 4 GB
Server : SQL server 2008 (RTM)
create table tableA (id int identity ,name varchar(50)) declare @i int set @i=0 while (@i<100) begin insert into tableA (name) select name from master.dbo.spt_values set @i=@i+1 end --select COUNT(*) from dbo.tableA --250600 go create table tableB (id int identity ,name varchar(50)) declare @i int set @i=0 while (@i<100) begin insert into tableB (name) select name from master.dbo.spt_values set @i=@i+1 end -- select COUNT(*) from dbo.tableB --250600 select * from dbo.tableA A join tableB B on (a.id=b.id)
Test1: Without Index
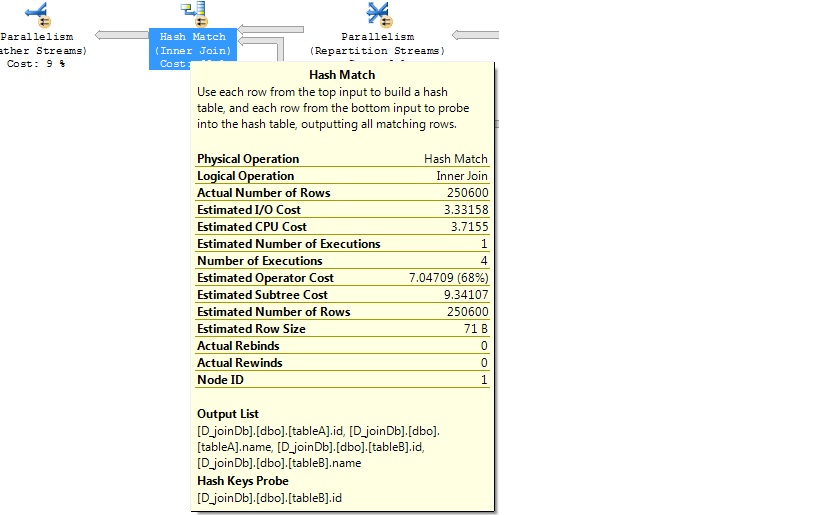
Let’s create a clustered index
create unique clustered index cx_tableA on tableA (id) create unique clustered index cx_tableB on tableB (id)
Test1: With Index
If either of the table has indexed then it goes hash join. I haven’t shown this picture here. You can drop either of the table indexes and test it.
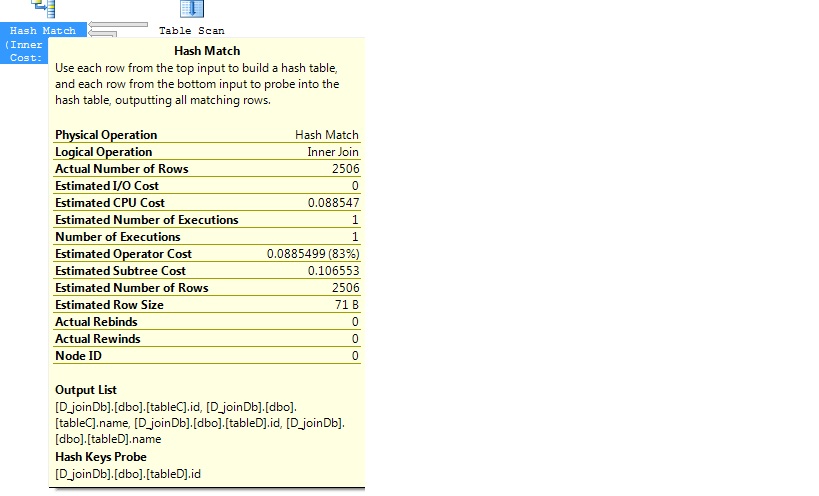
Test2: Without Index
Let’s create a medium table
create table tableC (id int identity,name varchar(50)) insert into tableC (name) select name from master.dbo.spt_values -- select COUNT(*) from dbo.tableC --2506 create table tableD (id int identity,name varchar(50)) insert into tableD (name) select name from master.dbo.spt_values select * from dbo.tableC C join tableD D on (C.id=D.id) -- select COUNT(*) from dbo.tableD --2506
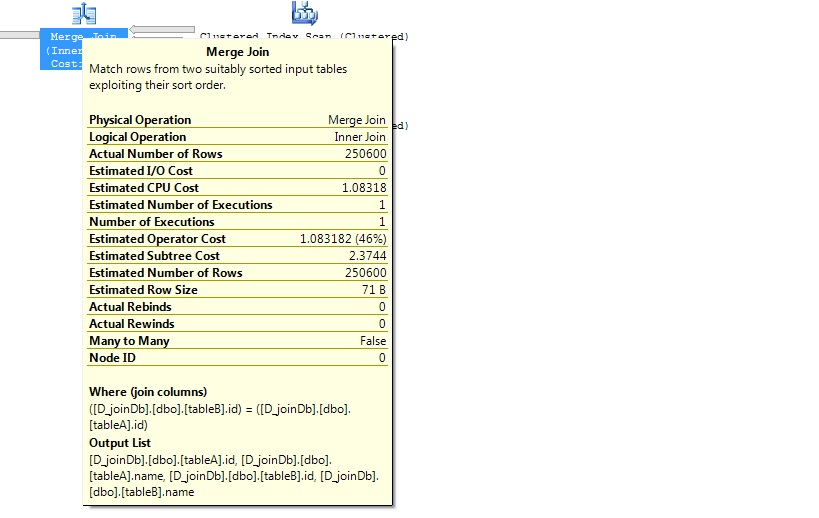
Test2: With Index
Let’s create a clustered index
create unique clustered index cx_tableC on tableC (id) create unique clustered index cx_tableD on tableD (id)

If either of the table has indexed then it goes merge join. I haven’t shown this picture here. You can drop either of the table indexes and test it.
Test3: Without Index
create table tableE (id int identity,name varchar(50)) insert into tableE (name) select top 10 name from master.dbo.spt_values -- select COUNT(*) from dbo.tableE --10 create table tableF (id int identity,name varchar(50)) insert into tableF (name) select top 10 name from master.dbo.spt_values -- select COUNT(*) from dbo.tableF --10
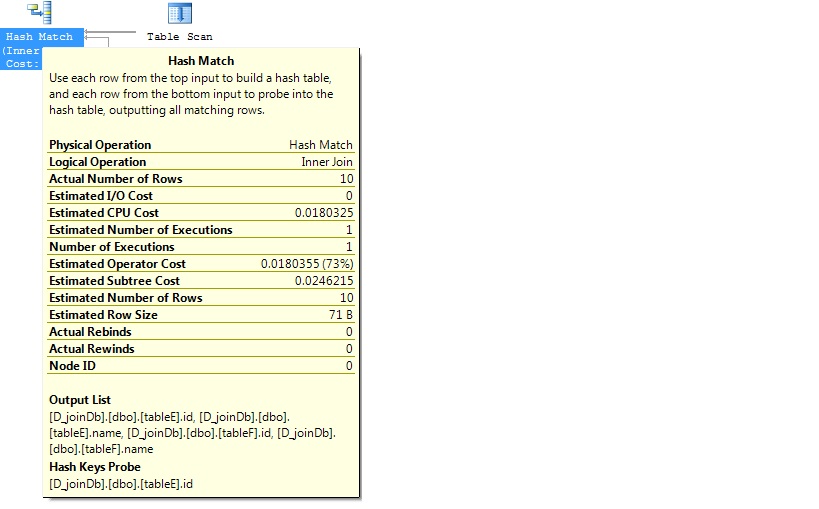
Let’s create a clustered index
create unique clustered index cx_tableE on tableE (id) create unique clustered index cx_tableF on tableF (id)
Test3: With Index
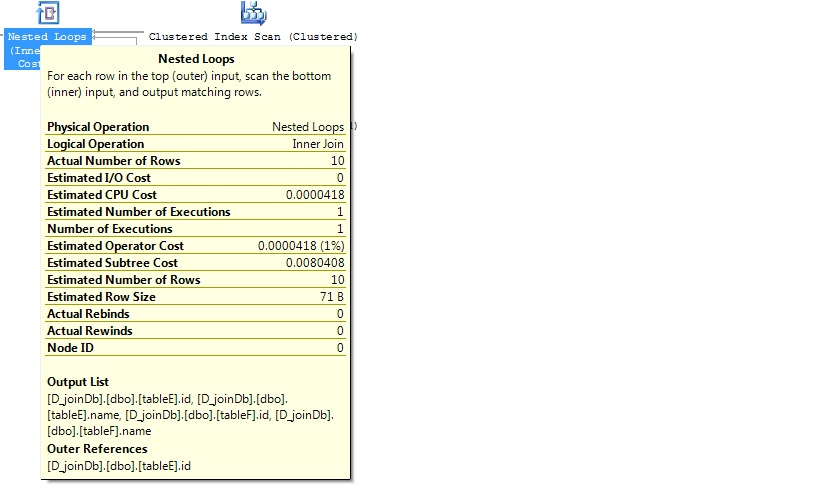
If either of the table has indexed then it goes Nested loop join. I haven’t shown this picture here. You can drop either of the table indexes and test it.
You can also join tables vice versa like big table Vs Medium table Vs small table
select * from dbo.tableA A join tableC C on (a.id=C.id) select * from dbo.tableA A join tableE E on (a.id=E.id) select * from dbo.tableC C join tableE E on (C.id=E.id)
In this case if all the table has indexed then it goes Nested loop join. If they don’t then hash join. If either of the table has indexed then it goes Nested loop join. I haven’t shown this picture here.
Still you can force optimizer to use any one of the internal joins, but it’s not good practice. The query optimizer is smart it will dynamically choose the best one.
Here just I used the merge hint so the optimizer goes to merge join instead of a hash join (Test1 without an index)
select * from dbo.tableA A join tableB B on (A.id=B.id)option (merge join) select * from dbo.tableA A inner merge join tableB B on (A.id=B.id)
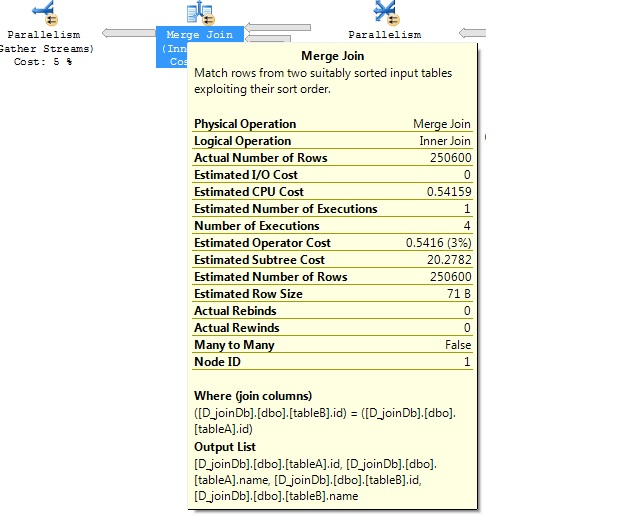
Table 1: Test uses a unique clustered index

From the table diagram:
- If both the tables have NO index then the query optimizer will choose “Hash joins” internally.
- If both the tables have indexes then the query optimizer will choose “Merge (For big tables) /Nested loop (For small tables)” internally.
- If either of the tables have indexes then the query optimizer will choose “Merge (For medium tables) /Hash (For big tables) /Nested loop (For small & big Vs small tables)” internally.
Table 1: Test using clustered index
(create clustered index cx_tableA on tableA (id))
| Table size | With index (Both) | Without Index(Both) | Either of table has index |
| Big (Both) | HASH | HASH | HASH |
| Medium (Both) | HASH | HASH | HASH |
| Small (Both) | NESTED LOOP | NESTED LOOP | HASH |
| Big Vs Small(medium) | HASH | HASH | HASH |
From the table diagram:
This test has done using without a unique clustered index. See if the index created without unique keyword then there is no guarantee SQL will not know its unique (data) so it will create 4-byte integer GUID unique-identifier by default.
Look the diagram there is no MERGE join if the clustered index created without unique.
Thanks @Dave for your email 🙂 . Now the second diagram added.
Conclusion:
Merge Join
Merge join is possible for the tables have an index on the join column. The index either clustered or covering non-clustered index. It’s best join for this circumstance. Why it’s best join? Because it needs an index for both the tables. So it’s already sorted and easily match and return the data.
Hash Join
Hash joins is possible for tables with no index (or) either of the big tables has indexed. It’s best join for this circumstance. Why it’s best join? Because it’s worked great for big tables with no index and run the query parallel (more than one processor) and give the best performance. Most of folk says its heavy lifter join.
Nested loop Join
Nested loop join is possible for small tables with index (or) either of the big tables have indexed. It’s best join for this circumstance. Why it’s best join? Because it works great for small tables like, compares each row from one table to each row from the other table ‘looping’.
For more: Read Gail Shaw’s blog. It has Craig Freedman’s link too. Why I gave Gail’s link instead of directly give Craig‘s link. It’s worth reading and most of my readers are from India and they have to read all her posts.
I hope now you can understand how the query optimizer will choose the most optimal join types.
36 Comments
Mandy Fox
Hi, hope you don’t mind me using your comment form to get in touch? It seemed the quickest and most pertinent method. As a fellow blogger, I couldn’t help noticing your site isn’t optimised for mobile users. Did you know the mobile market is 100 times bigger than the whole of the internet? There’s a video here that explains it all pretty well: http://ow.ly/6M4OF
If you have a few minutes, do have a look, I think you might be surprised at what you’re missing.
siva
Thanks for the post.
Muthukkumaran kaliyamoorthy
I’m glad you liked it.
Fausnaught
It is hard to find knowledgeable people on this specific topic, but you sound like you know very well what you’re writing about! Cheers
Muthukkumaran kaliyamoorthy
Thanks.
Abril
awesome blog, do you have twitter or facebook? i will bookmark this page thanks.
Muthukkumaran kaliyamoorthy
Thanks abril. My twitter and facebook accounts are there on the top page(follow me).
Muthukkumaran kaliyamoorthy
Where do you get/find my blog post links? Are you advertiser?
Please don’t post spam comment.
Dave
Hello muthukkumaran
Thanks for the cool post. I run your scripts but its seems missed some lines in your first test script. Fix it.
Muthukkumaran kaliyamoorthy
Thanks Dave. Now it’s updated.
Thanks for script testing & reading 🙂
Dave
Test1: With Index
I wrote a while loop as same like you but for me it shows hash join.
I want to confirm. can you fix your script!
Muthukkumaran kaliyamoorthy
Dave
Can you tell me your sql version. Also can you post me your tested scripted.In my test it goes merge join.
Thanks once again!
Skillington
Excellent! it is the word that comes to my mind when I look at your blog and when I read what you have to say. Your opinions are very much alike mine. I happy that I decided to enter your website and find out what you are interested in.
Dave
Hi Thanks! Mine 2008 r2.
I have tested the same code but I created clustered index without unique and row counts are vary (250800).
Yep you are right if I created the clustered index as unique it shows merge.
Muthukkumaran kaliyamoorthy
@dave Yeah its expected one. SQL knows its unique and its easily match it.
As i already said in my post it depends upon the following.
• It depends upon the table size
• It depends upon the index on the join column
• It depends upon the Sorted order on the join column
muthukkumaran
Roundup post : http://codegumbo.com/index.php/2011/10/10/tsql2sday-roundup/
Ignatius Gannon
Unusual icons on my desktop?
Muthukkumaran kaliyamoorthy
@Ignatius Gannon
Couldn’t get it. You mean the image is not shown clear.
gam
I really liked your blog! It helped me alot… Awesome. Exactly what I was looking for. Thanks!
Muthukkumaran kaliyamoorthy
Thanks.I’m glad it helps you.
Cliff Konicki
whoah this blog is fantastic i love reading your articles. Keep up the good work! You know, a lot of people are looking around for this info, you can aid them greatly.
Muthukkumaran kaliyamoorthy
Thanks Cliff Konicki
Gurupreet
Nice Explanation
Sandeep
Thanks Really Very good Explanation..
Pavan Bhardwaj
Really, awesome post
Keep it up
I like your work
I am also an blogger on: Code Imagine
Andy Russell
Very useful article, well written and informative – thanks !
Pratap
Hey very nice info…just learned abt them today and when tried more info for knowledge, was routed to ur blog..I really liked the comparison idea..good article..thanks for sharing the knowledge.
Britto
Awesome blog…
suhas
Awesome Blog. Explanation Physical joins made easy.
Thanks you!
Mohd Tahir Siddiqui
Hi, Muthukkumaran kaliyamoorthy
I am much thankful of this post. You solve my confusions. God bless you.
Muthukkumaran kaliyamoorthy
Hi Mohd,
I am glad it helped you.
preeti chourasiya
awesome
Suresh Sanga
Good one with explanation using example,help to understand clearly,Thank U 🙂
Muthukkumaran kaliyamoorthy
Thanks! Glad that it helped.
Coim
Good article .thanks for posting pls update new articles like this
kangraevents
Thank You for an amazing article, it was really helpful for me and loved to read this.