What is table partitioning?
Table partitioning is a way to divide a large table into smaller pieces as a partition logical unit. By default a table will be stored into single partition that is partition number 1. The data of partitioned tables and indexes divided into logical units that may be spread across more than one file and filegroup in case if we use file and filegroup method in the database creation, otherwise it will be stored into a single default MDF Primary file and filegroup.
Having multiple filegroup or single file group is depends on the application requirement it is not going to do anything with table partition for loading and unloading data if we put all in same filegroup or different. Having a different filegroup helps to implement backup restore with read only filegroup and assigning high performance disk for current OLTP data and low performance disk for historical data and run CheckDB filegrouo level etc.
In general, we do partition for larger tables to load and unload data quickly and rebuilds the index partition level etc. You can make an existing larger table to table partition. The idea is to make it smaller piece so that data load – insert and data unload –Delete (truncate) will be faster in the partition level instead of row by row. Since in table partition only do meta-data changes easily move data from one table to another table or partition.
Table partitioning mainly to load and unload data effectively and it is not for increase select query performance, unless each of our query has partition key column and to look the particular partition instead of scan all partitions. That is also called partition elimination. Even some cases we have no option to keep non aligned index and because of that, table partition reduce the select query performance also.
When do we use table partitioning?
If you have requirement where you get bluk data insert daily and delete them after x days or month you can consider testing with table partitioning.
When your data load-insert and archive-delete for large table takes more time and blocking other users. You can think to implement table partitioning. On performance point of view you can have both benefit and drawback based on the query written in where and join condition in your application. As long as the the query has partition elimination to look particular partition it will get benefited. Otherwise it has to scan all partition and will take more time, this will take more time than normal non clustered index scan. Since non clustered index mostly small.
Things and Technical Terms to know in Table Partitioning
Before partitioning just try test file and filegroup and understand how it is working if you are planning to go with extra files and filegroup other than default. Also if you are partition the table using date column understand how the date and time store with fractional seconds for date , datetime and datetime2(7) data types.
Technical Terms –Partition function, Partition scheme, Range LEFT, Range Right, Switch, Merge, Split & Truncate partition.
One line answers:
Partition function – By using this we can store data into multiple partitions based on the partition function value specified in the partition function creation. By default SQL store table in single partition.
In table partition we can decide how to partition like daily, weekly, monthly, quarterly and yearly based on the business requirement.
Partition scheme– Partition scheme tell which filegroup the data should be stored. Data will be stored based on the partition function and scheme specified. Example 2024 data should store into 2024 data file and filegroup and 2025 should store data into 2025 data file etc. By default MSSQL will have one filegroup called Primary and one MDF and LDF files.
Range LEFT – The boundary value is the last value in the left partition.
Range Right – The boundary value is the first value in the right partition.
Table partition Features
Aligned and Non Aligned Index
Aligned index table partitioning is a technique that uses the same partition scheme and column for both a table and its index. SQL needs the partitioning key to be explicitly defined in all unique indexes on partitioned tables. So that SQL can determine the uniqueness of that index by checking one partition. You can only able switch data if the indexes are aligned.
Non aligned index is creating table without having partition column and scheme specified.
Switch – Switch partition is move data in and out between a table using switch feature.
Truncate -Truncate partition will truncate the partition and leave as empty then we can merge it.
Split – When we have data stored in wrong partition we need to split it to the right partition.
We can do this in two ways 1) with data split and 2) without data split.
Merge – Merge partition will drop the existing partition and merge partition to the next partition for right range and take the merged last partition boundary value, make sure the partition is empty before merge otherwise both data will merge together.
Note: Workout all above table partition feature and understand how it works.
Use following system objects and understand which partition data is stored etc.
sys.partitions, sys.partition_schemes, sys.partition_functions, sys.partition_range_values
Partition Function
By default MSSQL will store all data into single partition that is partition number 1.
By using partition table function we can store data into multiple partitions based on the partition function value specified in the creation. This will help data load and unload effectively using the partition features.
MSDN: Creates a function in the current database that maps the rows of a table or index into partitions based on the values of a specified column. Using CREATE PARTITION FUNCTION is the first step in creating a partitioned table or index. A table or index can have a maximum of 15,000 partitions.
MSDN Example:
CREATE PARTITION FUNCTION myRangePF1 (int)
AS RANGE LEFT FOR VALUES (1, 100, 1000);
| Partition No | 1 | 2 | 3 | 4 |
| Values | col1 <= 1 | col1 > 1 AND col1 <= 100 | col1 > 100 AND col1 <=1000 | col1 > 1000 |
CREATE PARTITION FUNCTION myRangePF2 (int)
AS RANGE RIGHT FOR VALUES (1, 100, 1000);
| Partition No | 1 | 2 | 3 | 4 |
| Values | col1 < 1 | col1 >= 1 AND col1 < 100 | col1 >= 100 AND col1 < 1000 | col1 >= 1000 |
Partition Scheme
Partition scheme will store the data into file and filegroups based on the partition function and scheme specified. Example 2024 data should store into 2024 data file and filegroup and 2025 should store data into 2025 data file etc. By default MSSQL will have one filegroup called Primary and one MDF and LDF files.
Table partition scheme will create n+1 partition range boundaries for the given partition function.
MSDN: Creates a scheme in the current database that maps the partitions of a partitioned table or index to one or more filegroups. The values that map the rows of a table or index into partitions are specified in a partition function. A partition function must first be created in a CREATE PARTITION FUNCTION statement before creating a partition scheme.
MSDN Example:
CREATE PARTITION SCHEME myRangePS1 AS PARTITION myRangePF1 TO (test1fg, test2fg, test3fg, test4fg);
Right Range
The boundary value is the first value in the right partition.
Example Partition function boundaries are following.
Use the same code and change the right range to left in the partition function and test it out.
use master
go
alter database Test_Tbl_Partition set single_user with rollback immediate
drop database Test_Tbl_Partition
go
create database Test_Tbl_Partition
/*
go
use master
go
CREATE DATABASE [Test_Tbl_Partition]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'Test_Tbl_Partition', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\Test_Tbl_Partition.mdf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_april_2024]
( NAME = N'F_april_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_april_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_Before_2024]
( NAME = N'F_Before_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_Before_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_feb_2024]
( NAME = N'F_feb_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_feb_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_jan_2024]
( NAME = N'F_Jan_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_Jan_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_June_2024]
( NAME = N'F_junel_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_junel_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_march_2024]
( NAME = N'F_march_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_march_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ),
FILEGROUP [FG_May_2024]
( NAME = N'F_may_2024', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\F_may_2024.ndf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB )
LOG ON
( NAME = N'Test_Tbl_Partition_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\Test_Tbl_Partition_log.ldf' , SIZE = 73728KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
WITH CATALOG_COLLATION = DATABASE_DEFAULT, LEDGER = OFF
GO
*/
go
use Test_Tbl_Partition
go
-- create table in primary FG
CREATE TABLE [tbl_partition_test](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Date_Col] [datetime2](7) NOT NULL,
CONSTRAINT [PK_C1810429_tbl_partition_test] PRIMARY KEY CLUSTERED
(
[ID] ASC,
[Date_Col] ASC
)
)ON [Primary];
GO
-- insert into [tbl_partition_test] ([Date_Col]) values ('2020-12-31 00:00:00.0000000')
--/*
--YYY-MM-DD
insert into [tbl_partition_test] ([Date_Col]) values ('2023-12-31 00:00:00.0000000')
insert into [tbl_partition_test] ([Date_Col]) values ('2024-01-01 00:00:00.0000000')
insert into [tbl_partition_test] ([Date_Col]) values ('2024-02-01 00:00:00.0000000')
insert into [tbl_partition_test] ([Date_Col]) values ('2024-02-01 23:59:59.9999999')
insert into [tbl_partition_test] ([Date_Col]) values ('2024-03-01 00:00:00.0000000')
insert into [tbl_partition_test] ([Date_Col]) values ('2024-04-01 00:00:00.0000000')
insert into [tbl_partition_test] ([Date_Col]) values ('2024-05-01 00:00:00.0000000')
--*/
select * from [tbl_partition_test]
CREATE PARTITION FUNCTION PF_myDateRange ( [datetime2](7))
AS RANGE right FOR VALUES
(
-- data less than 2024-01-01 00:00:00.0000000
'2024-01-01 00:00:00.0000000',
-- data greater than and equal 2024-01-01 00:00:00.0000000 and less than to this date and time 2024-01-02 00:00:00.0000000
'2024-02-01 00:00:00.0000000',
-- data greater than and equal 2024-01-02 00:00:00.0000000 and less than to this date and time 2024-01-03 00:00:00.0000000
'2024-03-01 00:00:00.0000000',
-- data greater than and equal 2024-01-03 00:00:00.0000000 and less than to this date and time 2024-01-04 00:00:00.0000000
'2024-04-01 00:00:00.0000000',
-- data greater than equal 2024-01-05 00:00:00.0000000
'2024-05-01 00:00:00.0000000'
)
GO
CREATE PARTITION SCHEME PS_myPartitionScheme AS PARTITION PF_myDateRange ALL TO ([PRIMARY]);
--CREATE PARTITION SCHEME PS_myPartitionScheme AS PARTITION PF_myDateRange TO ([FG_Before_2024],[FG_jan_2024],[FG_feb_2024],[FG_march_2024],[FG_april_2024],[FG_May_2024],[FG_June_2024]);
--/*
/*
-- drop and create clusterd index and point tot partition scheme to make existing table into partition data alignment
drop index [PK_C1810429_tbl_partition_test] ON [tbl_partition_test]
alter table [tbl_partition_test] drop constraint [PK_C1810429_tbl_partition_test]
CREATE UNIQUE CLUSTERED INDEX [PK_C1810429_tbl_partition_test] ON [tbl_partition_test]
(
[ID] ASC,
[Date_Col] ASC
) ON PS_myPartitionScheme([Date_Col]);
GO
*/
CREATE UNIQUE CLUSTERED INDEX [PK_C1810429_tbl_partition_test] ON [tbl_partition_test]
(
[ID] ASC,
[Date_Col] ASC
)
WITH (DROP_EXISTING=ON)-- If the index is exists drop and create it.
ON PS_myPartitionScheme([Date_Col]); -- Important here is create the Index in the (PS_myPartitionScheme) Name so that it will use the specified filegroup.
--If we not use this dy defalut again goes to Primary Filegroup.
GO
--*/
Code to load sample data:
use Test_Tbl_Partition --Run this for 10 minutes and cancel it. You will get 3 million data DECLARE @DateTime DATETIME2(7) = '2024-01-01 00:00:00.0000001' -- max date pls one fractional WHILE @DateTime <= '2024-12-31 23:59:59.9999999' -- select getdate() BEGIN insert into [tbl_partition_test] ([Date_Col]) SELECT @DateTime --SET @DateTime = DATEADD(nanoSECOND, 50, @DateTime) SET @DateTime = DATEADD(HOUR, 1, @DateTime) END
Following is the image of same data insert. I took max date value after all insert for both left and right ranges to understand better. Why everyone says we must use Right range.
To dynamically create partition function and scheme.
https://amattas.medium.com/creating-partitions-using-dynamic-sql-d32187a67ec8
LEFT Range
The boundary value is the last value in the left partition.
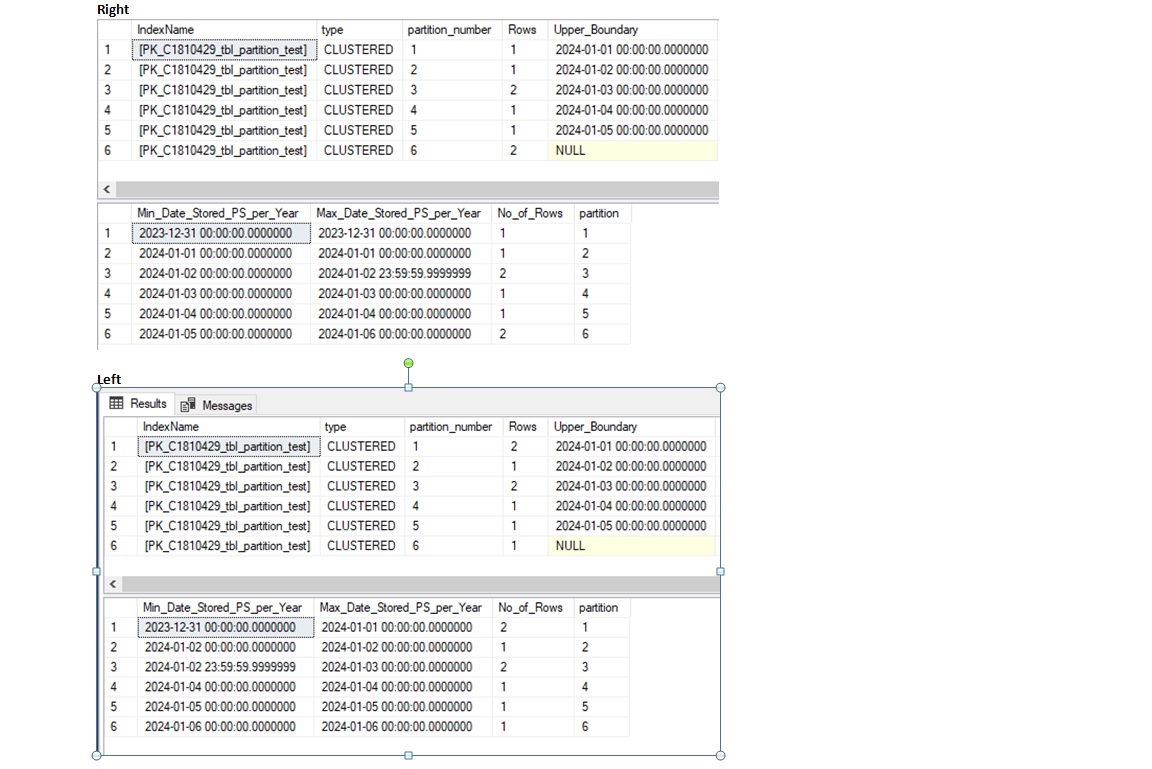
The problem in LFET range is when we split and add new partition it will be created before the last partition of left side.
Also the two same date in a day added will be going to be in two different partition even though both are same day – Look at the min and max value for particular partition ex: Partition 2 & 3 01-02-2024 00:00:00 12 AM data get inserted into before partition number 2 and 01-02-2024 23:59:59.9999999 11:59 PM inserted into partition number 3. That’s the reason we generally use RIGHT range for most of the cases.
Here is the boundary details:
Except first and last partition, In RIGHT partition the values are stored including lower boundary value to before the upper boundary value.
| RIGHT | |||
| partition_number | Lower_Boundary | Details | Upper_Boundary |
| 1 | Before 1-1-2024 | < 1-1-2024 | 1-1-2024 |
| 2 | 1-1-2024 | >= 1-1-2024 < 1-2-2024 | 1-2-2024 |
| 3 | 1-2-2024 | >= 1-2-2024 < 1-3-2024 | 1-3-2024 |
| 4 | 1-3-2024 | >= 1-3-2024 < 1-4-2024 | 1-4-2024 |
| 5 | 1-4-2024 | >= 1-4-2024 < 1-5-2024 | 1-5-2024 |
| 6 | 1-5-2024 | >= 1-5-2024 | NULL After 1-5-2024 |
Except first and last partition, In LEFT partition the values are stored after the lower boundary value to including the upper boundary value.
| LEFT | |||
| partition_number | Lower_Boundary | Details | Upper_Boundary |
| 1 | Before 1-1-2024 | <= 1-1-2024 | 1-1-2024 |
| 2 | 1-1-2024 | > 1-1-2024 <= 1-2-2024 | 1-2-2024 |
| 3 | 1-2-2024 | > 1-2-2024 <= 1-3-2024 | 1-3-2024 |
| 4 | 1-3-2024 | > 1-4-2024 <= 1-4-2024 | 1-4-2024 |
| 5 | 1-4-2024 | > 1-5-2024 <= 1-6-2024 | 1-5-2024 |
| 6 | 1-5-2024 | > 1-6-2024 | NULL After 1-5-2024 |
For more about range issues and fix.
https://www.dbdelta.com/remediating-a-table-partitioning-mess/
Some more points:
SQL needs the partitioning key to be explicitly defined in all unique indexes on partitioned tables. This is so that SQL can determine the uniqueness of that index by checking one partition.
https://dbafromthecold.com/2018/02/21/indexing-and-partitioning/
2 Comments
Srilekha
Hi,
Great Article! Your insights are spot on Table Partition Microsoft SQL server part 1. I especially appreciate your points. You’ve done your research. Keep up the excellent work! Looking forward to reading more from you.
Here is sharing Informatica Admin Online Training related stuff that may be helpful to you.
Informatica Admin Training
GoLogica
Hi,
Great Article! Your insights are spot on in Incredicool.The Ultimate Solution for Social Media Growth. I especially appreciate your points. You’ve done your research. Keep up the excellent work! I’m looking forward to reading more from you.
Here is sharing Oracle Customer to Meter Training related stuff that may be helpful to you.